Introduction

Over a decade ago I wrote an article called “Worthy but Dull” about backups and archiving. It’s recently been a hot topic of discussion in an online group for photographers I participate in linked to Derrick Story’s podcast. I thought it was well overdue for an update. Whilst technology has moved on, many of the concepts remain the same.
First, a little context about my current requirements and experience. The data I need to protect is both personal and work-related. The commercial data is mainly video footage captured as part of a video production business. The video business is spread over two locations. The first location is for post-production and the data resides on a QNAP TVS-1283T3 NAS with a limited capacity local backup (QNAP TR004). The second location is mostly admin and has a QNAP TS-672XT NAS for primary data and a QNAP TS-1635 NAS for backup (including long-term backup for the post-production site). The two admin site NASs are linked on a 10GBE network and there is also a capability to copy to LTO6 tape. There are numerous subsidiary ad-hoc storage devices connected to the clients but let’s ignore those for the moment. We are a small team but our levels of storage are probably into the top end of prosumer levels. Our set-up is no paragon of virtue and I am constantly in a state of angst about how to improve it.
In a previous life, I had to consider backup and archival for much larger commercial systems. At the core of designing a solution are risk and cost. These are balancing factors and sit in opposition. Reducing risk costs money and that cost is not linear. The closer you try and get the risk to zero, the more the cost will spiral.
First of all, we have to distinguish between backup and archive. These terms are often used interchangeably but they do have a separate purpose. Backup is the one that is directly related to risk. Your backup strategy is there to reduce risk. It is primarily concerned with work that is in progress or highly likely to get accessed. In a commercial environment, this is often tied into a Disaster Recovery Plan (DRP) or a Business Continuity Plan (BCP). These differ mainly in scale. BCP looks at how can I get working again as soon as possible or keep working without your full resources for a short period. DRP is more about recovering from various large-scale interruptions or total loss. The business terms may sound over the top for a prosumer but the principles of risk analysis are just as valid outside of big business.
You need to decide:
How much work you are prepared to lose? For commercial organisations, data loss will come with a cost. For personal data, the real cost may be more sentimental.
How long you are prepared to wait to get it back?
How much time you would be prepared to put into recovering things e.g like reloading software?
Archiving is different in that it is an operational decision. It is about treating material that you expect to use infrequently differently to that which is more likely to be needed. Even in my simple set-up, I have some storage that is speedier or more expensive or more difficult to extend than others. I really don’t want to waste that by filling it full of stuff I do not expect to access. I also don’t want to have to search through all that static data looking for what I am currently working on. However, this is not data I will never conceivably look at again. The proper place for that is the trash can! Original source files are a good example. It’s best practice to keep them, but access will be rare. You don’t need them handy, but you do need to be able to get to them if you need to.
Once you have placed data in an Archive this does not mean that you don’t also need to think about it in your Backup Strategy. However, the approach you take will probably be different from that in your working data.
Risks
Storage Failure
This is the most common form of data loss. Hard disks are mechanical devices working on very fine tolerances. They are vulnerable to shock and environmental issues as well as wear and tear. Flash memory devices are more durable but have their own eccentricities which can affect longevity. Optical disks are vulnerable to poor handling and decay. Tape-based media have a good reputation for durability, but they are still a magnetic medium and they can wear or snag whilst being read.
The mitigation for storage failure is duplication. If your data is on two drives the mean time between failure (MTBF) is doubled. That’s good but the real key is that the chances that both fail at exactly the same time become tiny. You can duplicate using backup software to a different device, use folder synchronisation or Time Machine on Apple. The purest form of duplication is mirroring (also known as RAID 1). This is either software or hardware-controlled exact and real-time duplication of two drives. I will come back to this in a bit more detail. Mirroring is built into OSX at the software level and many PCs have it at the BIOS level as a feature of their motherboard.
Data Corruption
This is not the failure of the data being read on the drive, this is an application error that writes bad data onto your drive. The mitigation for data corruption is versioning. This is built into Time Machine and most backup software will have versioning options. However, unlike storage failure, mirroring is not a mitigation, it will have two identically corrupt files.
Version Control brings a couple of issues of its own. The first is that your backup storage requirements can grow much faster than your primary storage depending on how you configure the versioning options. The second is that metadata and actual data can get out of sync. Apple Final Cut Pro is a good example of this. An FCP library is a container file. Dig inside and you will find media files and a lot of metadata. Along with the original media data are things like render files, transcode files and proxy files. Render files are a pain in version control as they are big and change frequently. If you are trying to restore a library to a point in time getting the media and the metadata to match can be problematic - rebuilding from lots of versions.
Theft and Disaster
It seems an inevitable feature of the nature of the criminals that they are not going to leave that shiny drive array sat next to your PC when they are ransacking your place out of the goodness of their hearts. Given time they are going to take anything plugged into your surge protectors and then they are going to nick those too! This is the same with fire, flood and other acts of God. A wireless device like a Time Capsule may escape notice but you can’t put it anywhere where the wireless signal will be poor. A proper fire safe is probably beyond the reach of the prosumer. The only option, therefore, is to get the data somewhere else. This can be a physical location (my Dad’s house for me) or a Cloud location.
Virus & Cyber-Security
Here the threat is to the data itself and the hardware it sits on. Malicious code can brick your machine or force you to quarantine it from your own and public networks. Hackers may seek to steal your data from your primary location or your backups. If you have material of high sensitivity this may limit your backup options. The mitigation here is to prevent illegal access from ever happening. Once your firewall is breached, then the mitigations are similar to Data Corruption. A recent type of cyber attack comes in the form of ransomware. Here the hackers encrypt your data and force you to pay a ransom to decrypt it again. In recent times I have had warnings from QNAP that was NASs are now being targeted.
Running Out of Space
Is this really a risk? Probably not literally, but it tends to cause all kinds of other issues. The first problem is that things tend to break when the space runs out: files get corrupted, background processes fail to run etc. This may be something that is not immediately noticed. Secondly, things tend to slow to a crawl as the system struggles to find a good place to put things. There is also a tendency for you to start putting things where you know they shouldn’t be because there is no room in the right location (or is that just me?). One thing my long years in the IT game taught me is that what seems a ludicrous amount of storage today will seem merely adequate in just a few years.
Storage Tech Primer
RAID - redundant array of independent disks
RAID (/reɪd/; "redundant array of inexpensive disks"[1] or "redundant array of independent disks"[2]) is a data storage virtualization technology that combines multiple physical disk drive components into one or more logical units for the purposes of data redundancy, performance improvement, or both. Wikipedia
The most basic forms of RAID can use just two disks and can be seen in many entry-level storage devices. RAID 0 stripes data across drives. You get the combined speed and capacity of the two drives but double the risk of failure. It is a performance option not suitable for backups. RAID 1 maintains copies of the data across both drives. Performance is similar to a single drive, but you only have the same capacity as a single drive. It does half the risk of failure though.
Once you get beyond 2 drives, new options become available. Depending on just how many drives you have you can start to play RAID bingo. There are a bewildering number of variants of RAID available, each with its own subtle characteristics in terms of safety, performance and capacity. Few devices support every possible option so it’s best to do your research on RAID levels, find the one which best matches your needs, then look for devices that support that RAID level. To give an illustration, I am going to look at one of the most commonly implemented RAID levels. RAID 5 gives good capacity and middling safety and performance. In a RAID 5 array, you lose one drive’s worth of capacity from the array and you need at least 3 drives. So a 4 x 10TB RAID 5 array gives around 30TB of space. The more drives you have, the better the ratio of what you get to use. The same formula applies to performance. You multiply the data performance by the number of drives minus 1. So 4x 250Mbps drives would theoretically give 750Mbps. The actual speed will depend on the interface to the client and the performance of the RAID controller.
For larger installations, exceeding the maximum primary drive size you are backing up is essential. Remember, backups may contain multiple versions of a file, so you may need much more space for backup than you are using for your primary data. This will definitely be the case if you use version control. Some NAS drives offer automatic de-duplication but I have not been brave enough to turn that on.
One last point about drive arrays - they can be touchy blighters! All arrays have some hard maths going on in the background to make sure they are OK. If anything goes wrong, then they have to either rebuild or go through diagnostics. Now, this is way better than losing a whole load of data, but it will at the very least reduce performance while it happens or even take the device off-line. This can take hours or even days. I’d highly recommend a UPS to avoid sudden shutdowns.
They are also fussy about drives. Ideally, you want every drive to be the same type and capacity. Any variation and the whole array will be dictated by the lowest common denominator for speed and capacity. For example, if you built a RAID 5 array of 4x 2TB disks it would be 6TB net. If you used 3x 2TB + 1TB it would only be 3TB net. There is a slight risk from buying a lot of identical drives all at once that they might be from the same production batch. It sounds like a remote chance, but I had 3 drives from a batch die in quick succession once. Are you beginning to see why I have data paranoia?
Increasing space later by adding more drives into empty bays is usually possible but can impact performance for a while as the data is shuffled around the drives in the array. Things like RAID 5 protect you from a single drive failure. There are RAID types like RAID 6 and RAID 10 that can survive 2 simultaneous drive failures at the cost of capacity.
One thing to be aware of is that not all enclosures designed to hold arrays have the interface controllers built-in. If you see a drive array described as a JBOD (Just a bunch of disks) then they will require a controller card to be added to your client. If your client cannot take PCIe cards, then a software raid app like SoftRAID may be a solution.
Interfaces
If you are not putting drives inside your client device then you will need to attach them via some kind of interface.
USB
USB is the most common form of interface standard. Unfortunately, it has evolved into a confusing mix of capabilities and connectors over its 26-year life. Unless your data volume is tiny, anything less than USB 3.0 is best avoided. USB 3.0 supports 5Gbps and is fine for most HDD-based solutions with less than 4 drives. Most modern client devices will support it as long as you have the right cable to suit your devices. For SSDs and large HDD arrays you really need at least the 10Gbps of USB3.1. For the fastest NVME SSDs, you need USB3.2 (20Gbps) or 4 (40Gbps) which are USB Type C only. It is really important to check your client, device and cable can support the maximum data rate or you might be disappointed.

Thunderbolt

Thunderbolt (TB) was originally an Intel/Apple collaboration and is a higher performance and more capable interface than USB. The most common implementation now is TB3. It can carry 40Gbps of data and can be daisy-chained. The newer and rarer TB4 has the same speed but allows Thunderbolt 4 hubs to be attached - giving another way to attach more devices to a client. Despite using a Type-C connector, compatibility with USB3/4 is highly device-dependent. Certified TB cables are marked with a symbol. Thunderbolt devices and cables are always at a premium to USB equivalents.
Ethernet and WiFi
Ethernet is rarely used with storage devices directly but is typically the way that storage servers connect with clients. Normal Ethernet (1GBE) has a theoretical speed of 1Gbps but that speed is much more variable than a direct connection. WiFi speed is even more variable. 10GbE can give a good performance, but the components are pricier and it's much less common in clients and servers. . The connections are either by optical SFP connections or RJ45 (like standard ethernet). It is starting to get a bit more common to see intermediate speed devices hit the market at lower prices at 2.5GbE or 5GbE. There are even faster ethernet speeds than 10GbE available, but this equipment is still quite esoteric and expensive.
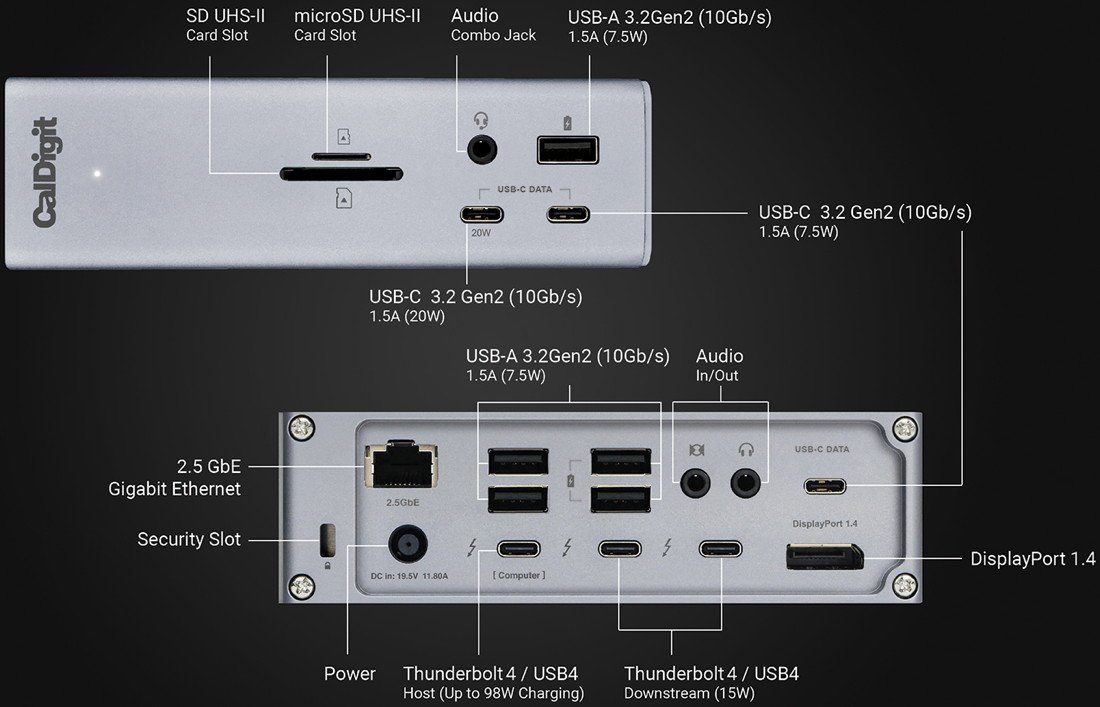
The Caldigit TS4 is an example of a device which has a faster 2.5GbE port rather than the more typical 1GbE.
Devices
Internal Options
Many devices like laptops and all-in-ones (eg iMac) now only have a single internal storage device that are non-upgradable parts. These tend to be fast Solid State Drives (SSD) drives with limited capacity unless you spend a lot. Desktop PCs still tend to have multiple storage options. Typically this will be configured as a small fast volume on SSD and a larger, slower volume on Hard Disk Drive (HDD).
External Hard Drives
Absolutely massive choice of devices here so we need to split them into smaller categories. They come in a variety of interfaces and may be pre-formatted for macOS or Windows (although this is usually changeable). They also can come with a variety of interfaces but the most common now are USB3-4 or Thunderbolt 3-4.
Bus-powered

Sandisk Extreme Pro Thunderbolt SSD drive is both very compact and fast.
These are now most commonly 2.5’ HDDs or NVME SSDs in a protective case. Their low power draw means that they only require an interface cable and don’t require a power brick. The HDDs are relatively inexpensive and are typically in the 1-4TB range. Their speed is only about 150MBps, which is well within the capability of USB3.0. The NVME SSDs are smaller and more expensive and most are in the 250MB-2TB capacity range. There are larger ones, but they are prohibitively expensive. There are a lot of factors that can dictate external performance but the key one is probably the interface. Older USB standards will be the limiting factor on many drives. Higher speeds are available with the latest USB standards to Thunderbolt, but these will cost more for the same capacity. Your client device may limit what interfaces you can use and the performance it can achieve.
Desktop
These are normally a 3.5” SATA drive in a housing. They need an interface cable and a power supply and come in the 1TB to 18TB range. The speed tends to be in the 150-250MBps range. It is well within the capabilities of USB3. It is the cheapest way to big capacity.

Western Digital USB external HDD
“Toaster”
This is a drive interface and a SATA connection with a disk loading slot. Effectively the skeleton of Desktop External drive. Most fit either size of SATA drive, but for backup, larger drives are the obvious choice. It allows you to work with drives like you might have with tapes but remember tapes were born to be handled. Bare drives are naked and vulnerable.

Flash Drives
These are stick-like drives that are solid state. Though small and very portable, they are limited to about 128GB currently. USB3 is the most common interface. These have not grown much in capacity as the higher capacity market is dominated by the faster, larger capacity NVME drives.
Drive Arrays
I am calling anything with more than one drive an array but the breadth of devices that covers is pretty massive in terms of capacity, cost and implementation. Let’s look at them in terms of architecture first.
Direct Attached Storage (DAS)
The simplest kind is a direct attached storage device. In this format, the drives attach just like a single external drive. Intelligence in the device is limited. Normally, it is just a RAID controller card and some bays to hold drives. Prosumer versions tend to look like stretched versions of a maker’s external drives and have just 2 drives. Usually, only RAID 1 (mirroring) and RAID 0 (striping) are offered. If you can fit your backups in this capacity, these drives in RAID 1 are a safe pair of hands and good value if inflexible. Slightly more expensive are versions that have removable drive caddies. This opens up the world of drive rotation and they are a lot easier to get back online if you do have a drive go down inside. Some of the manufacturers tie you into buying proprietary drives though, which adds to the potential expense.

OWC Thunderbay 4
Storage Robots
This term comes from Drobo and they are the leaders in this field. They were designed to be a more user-friendly alternative to RAID (which can feel like a combined IT and Maths exam to set up) and more tolerant of mixed drives. Unfortunately, the future of Drobo, the company, is currently in doubt. It would be a risky choice to invest in now.
Network Attached Storage (NAS)
A NAS is really a small server optimised for sharing data. The RAID arrays are the same in principle as a DAS RAID device, but a NAS is seen as a completely separate device on your network whereas a direct-attached device appears as a local disk on your client. The benefit is that multiple computers can use the device as a backup target.

My NAS drives
These are servers, so while they tend to look superficially the same, performance can vary widely due to CPU, memory, network and disk controllers. There is also the quality of the interface (normally browser-based) to consider. High-performance NAS can get close to DAS speeds using Thunderbolt or 10GBE. They can also offer additional services like running a Plex Server, acting as a private cloud server or recording CCTV feeds. The more basic units tend to focus on being a backup target. Strong competition in the entry-level sector keeps prices down so they offer good value if your priority is capacity and consolidation, not performance.
Optical Storage
This option has disappeared from most clients these days. The capacities are now looking a bit limited at a maximum of 100GB. It still is an option for archival if you invest in the right media and have a low data volume.
Cloud Storage
This is an internet service provision where your data is stored in a data centre operated by a third party. This storage will be enterprise-class, high-redundancy and high-availability. All you need to do is set up an account and run a client utility on your PC. Most companies will offer different subscription models to suit users who have different size requirements or multiple devices. They are split into two main types of service, synchronisation and backup.
Dropbox is the best known of the synchronisers. Rather than back up your whole disk, you place data in a specified virtual folder structure. The Dropbox client then replicates this in the cloud. Any device you have Dropbox on, including mobile devices like smartphones, can access the data or you can go through a web client. You can even elect to share folders with other people you nominate. This is really designed for people who want to collaborate with others or tend to use multiple devices. It’s not really meant as a backup solution. It’s great for ad-hoc backups of relatively small amounts of data though.
The second type of server is aimed at the backup market. Providers include people like Carbonite, Backblaze and CrashPlan. They may also offer a hard disk restore or seeding option if the shipping time would be quicker than doing it over the net.
Arguably the biggest issue with a Cloud service is that you lose a degree of control over your data. All the companies publish their policies on security and encryption but once it is in the Cloud you can never truly be sure where it is or who can access it. Unless you are a specialist it should be the case that they are better at security than you are, but they are also a more obvious target. Hackers or disgruntled staff are not the only risks - what if the company goes out of business? If this is just a backup of your holiday movies from Mallorca, then it’s probably not an issue. If it is confidential work for clients then you need to take this into account.
Other People Disks
This is a service that CrashPlan introduced me to. Their client allows backups to other devices running CrashPlan. This can be on a private network or via the internet. The expectation is that this will be a “buddy” system where you agree to provide a reciprocal arrangement with someone you trust. The performance limitation will be primarily the link you choose. A private network should be much faster than an internet link. A hard disk starter backup will probably be advisable. It’s unlikely that your mate is going to have the same level of kit as a Cloud-based service but at least you “know where they live”.
Tape
It may be old-school, but tape is still a very effective option for both archiving and backup. The standard that is best supported for big data volumes is called LTO. If you do a bit of research, you will see numbers after that and these are significant. It refers to the generation of the standard. Each generation has grown in tape capacity and data rate. Backwards and forward compatibility is enshrined in the standard as are the expected life and re-uses a tape should manage. This is an enterprise-class solution which means heavy-duty, fast, reliable and expensive. Most of that cost though is upfront, the tapes themselves are less expensive than other mediums. You are going to need to have a lot of data though before you break even with disk-based alternatives. With its linear nature and long data retention period, the best use for tape is archiving.

mLogic produces an LTO Tape Drive with a Thunderbolt connection
Archiving
Archiving is “cut and paste” to Backup’s “Copy and Paste”. If the data you are archiving still exists in its original place when you started then you didn’t really archive it, you just backed it up.
Why archive?
So if we haven’t improved our data security by archiving it why even bother? Well, there are several reasons why it is beneficial to do so.
Freeing up scarce resources
Perhaps you edit on a laptop in the field and, to maximise your performance, you have a fast but small SSD drive. You would soon run out of space on that SSD if you leave old projects on there. Some NLEs have media manager functions that can reduce a project to just the assets used when they consolidate and move a project.
Move to safer environment
Resources like laptops, portable drives and fast RAID 0 arrays have inherently more risk attached to them. Moving data to a less risky environment long-term is advisable.
Allowing a different backup regime
An archive isn't a copy. So archives need backing up like everything else. However, they are going to have a different risk profile and data change rate to projects in progress. It makes no sense to tie up resources backing up the same file every night when there is only a tiny chance it will change. If you do get to a situation where an old project needs substantial rework then it should be moved out of the archive back into the work-in-progress storage.
Data Retention Period
It would be nice to think we could pop a disk with are archived data in a cupboard and we would always be able to access it. Unfortunately, HDDs are like combustion engines - they don’t like to be overworked or left standing unused. I have some ancient drives that fire up just fine whilst more recent ones responded with the terrible “click of death”. SSD life is more of an unknown as the technology is younger. In my experience, HDD sometimes partially fail and you can still extract data off them. SSD failures seem rarer but tend to be catastrophic.
Cataloging
You have to assume that, by the time you need something in the archive, you will have forgotten all about it or where you put it. At my age, this is almost certainly true. So how do you find stuff when people ask? Perhaps you are just interested in finding something to use as stock footage in another project and just want to look on spec.
Folder and naming conventions
This is the place to start. A degree of orderliness is essential if you want to be able to find things. How far you have to go with this probably depends on your working environment. There are defined practices for movie and broadcast that you can use but these could be overkill and bring in a new level of jargon. Some products may generate or impose the structure for you. If you are using multiple software solutions sometimes you may have some conflicts. My own general principle has to be to try and keep any software bin structures and physical folder structures in sync as much as possible. Try and be descriptive with the project folder names. If you are going to use any coding schemes then you need to be consistent and you need to make sure the key or index is accessible.
Metadata
With Final Cut Pro X, Apple moved to a metadata-focused model from a bin-based one (much to the consternation of the editing community). To me, this wasn't too much of a shock to adjust to. Not because of iMovie but because this is the same model that Aperture had used. As a database guy, I appreciate that tagging is able to encode the multiple attributes that a clip possesses in a way bins can’t without a lot of duplication. However, you have to be disciplined about it. Video is a bit sparse for metadata compared to stills with their well-established EXIF standard. However, I think this will change over time and more metadata will arrive with the files themselves. One of the interesting features of FCPX was auto-tagging based on analysis. For example, it attempts to tag clips as wide shots or close-ups or for shakiness. Adobe has some interesting technologies for voice recognition which could also find their way into metadata.
Off-line Cataloguing
If you use tapes or a tape-like workflow with other media, then you are going to need to generate a catalog. This is because your data is sat in a cupboard somewhere and is not available for searching. So you need to capture the data structure and metadata into a stand-alone database that remains on-line. You also need a physical indexing system so that when you search the catalog you can go straight to the right disk or tape in the cupboard.
Retrieval
Whether it’s an archive tape or a backup disk it's utterly useless if you can’t read it. Some LTO tapes are guaranteed for 40 years. That’s a long time in computing years. 40ish years ago, in 1981, I was in a team with three friends and won our school its first computer (a BBC Micro) in an inter-schools quiz on TV. I think I would struggle to read files a BBC Micro saved onto a cassette tape these days. To be honest it was a bit hit and miss in 1981. I have never re-used my DV video tapes and they acted as an archive once I had transcoded the footage onto to disk. However, my aging DV camcorders are getting a bit flakey. When the last one dies I lose access to my archive and will be scouring eBay.
To ensure retrieval, you often need to transfer the data to a newer format prior to the old format being obsolete. However, you need to be mindful of retaining as much quality as possible. In the heyday of DV and DVD, burning to a DVD may have seemed a decent archive solution. However, the transcode to MPEG2 within the DVD’s storage limit may have degraded the image. However, a data DVD backup of AVI files created in the DV codec should be a true copy of what is on the tape. But how long will that codec or file format be readable? Always be on your guard for technical obsolescence, whether it be hardware or software, and be planning your transfer solution.
Hidden Costs
Some costs are easy to calculate: investment in hardware, monthly cloud subscriptions etc.. Other costs can be a bit more stealthy. As I write this UK energy prices are at an all time high and still rising. I decided to monitor the energy being used in my office and was shocked when I realised it was predicted to cost me between £600-£1000 per annum. I do have a lot of equipment in there and it has forced me to review how much of it I really need.
Keeping large amounts of data live and then needing to back that up in my setup means running 2 NAS servers. They are always on. They are not always busy but even when not active with their primary task they tend to run RAID scrubbing, indexing, virus checks etc. I haven’t got individual measurements yet, but I will be doing those during my review and I will add the results when I can. A tape or disk in a drawer doesn’t consume energy. The energy costs are included in a Cloud subscription.
SUMMARY
How would I answer the questions I laid out earlier for my own purposes?
So is my set-up is a paragon of virtue?
Err...not so much. Part of the reason I am informed on this topic is I am perpetually in search of that ideal solution. I am more of an experimenter than a completer finisher so I am always wrestling with finding a method and not quite as good at implementing it. However, imperfect as it maybe, I do have some of the risks mitigated. Lets go back to my basic risk questions and I will answer them for myself:
How much work am I prepared to lose?
Not much, it's not important data to anyone else, but I would hate to lose it. My inner squirrel can’t cope with that.
How long am I prepared to wait to get it back?
No rush, as long as I know I can get it back time is not a big issue
How much time would I be prepared to put into reloading things like software?
I have a low tolerance for repeating things I have already done. I have loads of software & plugins and the like. I am prepared to lay out some cash to avoid that pain.
So how am I doing in mitigation of risks then?
Storage Failure
I am in transition between clients at the moment. My iMac has 2TB external drive as a Time Machine target. My MacBook Pro is backing up to iCloud. My Photo and Video data is on a NAS with a RAID 5 array and that backs up to a second NAS also with RAID 5. Periodically, I back some of that to LTO tape which goes off-site
Data Corruption
Time Machine is a versioning solution so is good protection for the local files. My media doesn’t alter too much once it is processed. It would take a lot of storage space to version control Final Cut. However, it does its own metadata backups and can regenerate render, proxy and transcode files.
Theft and Disaster
For things not in the cloud, I would need to recover from LTO tape. The infrequency I update this is one of the main weaknesses in my setup.
Virus and Security
I am a Mac user so the threat has traditionally been lower. However, I have my doubts this will continue given Apple’s rise in market share and No1 company status. I keep up-to-date with software updates on all devices and I have anti-virus and firewalls running on my clients and NAS drives. I don’t have significant Cloud-based assets to be under threat.
Archiving
I do move things from the client drives to the NAS if they start taking up significant space. Low priority, high volume data I might store on external drives and not backup (e.g. Disk Images taken prior to OS upgrades). LTO is another option for things with a very low chance of reuse.
So if you know better, what’s holding you back?
Well, there is cash for a start. It’s money well spent, but this is a hobby and there are so many, many things on my wish list... damn you Internet.
Once you have committed to a drive size/type in a RAID array then you are kind of stuck with it. If you start reaching capacity then you need to archive, add an expansion unit or rebuild the array with bigger drives.
I keep all the Cloud services under review. Cost, capacity and time have been the issues. The bulk of my data is on the NAS and that tends to exclude some of the subscriptions aimed at consumers. In the UK, you don’t always have access to the seeding or recovery services to get your data backed up or recovered quickly. There are some archival services starting to appear that offer lower costs for static data, but the set-up is a bit complicated and the actual costs are difficult to predict.
To optimise your set-up, you have to keep your data under review and be aware of the risks. It is worth monitoring the storage device market and its costs as it is always changing. The major Cloud services are also always tweaking their offerings and subscription models. New start-ups often appear focused on a particular niche and one of those might be perfect for your needs. Just be aware that many smaller services are using the cloud servers of a bigger vendor like AWS. There have been Cloud services that have gone bust and that hasn’t always gone well for their customers and their data. It’s best to research a company well before you commit to it.